EMNLP2025 | SFT与RL的结合,vivo AI Lab提出新的后训练方法
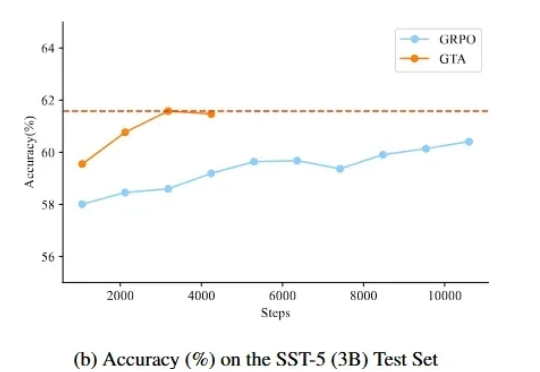
EMNLP2025 | SFT与RL的结合,vivo AI Lab提出新的后训练方法监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
来自主题: AI技术研报
8564 点击 2025-09-23 14:59
 搜索
搜索
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
作为开放世界游戏的标杆,GTA 系列不仅在游戏圈声名赫赫。尤其是在 AI 驱动的视频生成、三维生成或是世界模型等领域里,研究者们不仅采用游戏内场景为训练数据,更将生成类 GTA 的完整世界作为长久以来的目标。